Quaisr Platform
Digitalise faster
Maximise the value of existing modelling & simulation efforts through standardisation and connectivity.
Modelling & simulation integration
- Integrate your existing modelling & simulation ecosystem to create end-to-end workflows.
Existing data sources
- Integrate custom analyses with enterprise ERP and PLM systems.
Data-driven decision making
- Connect workflows to built-in optimisation and AI algorithms and unlock simulation-backed decision making.
Knowledge management
- Track history, knowledge and insights in one consistent place.
Rapid no-code app creation
- Share in-house workflows across teams and accelerate democratisation.
Enterprise deployment
- Deploy workflows securely at scale, while governing access, and monitoring uptake and usage for compliance.
Quaisr Solutions
SimOps industrial use cases
Engineering teams use Quaisr to operationalise solutions.
- Chemicals
- Reduce physical experimentation.Supply chain carbon footprint.Virtual laboratory.
- Learn more
- Consumer Goods
- Reduce physical experimentation.Increase product shelf life.Reduce line breakdowns.
- Learn more
- Energy
- De-risk scenario planning.Offshore wind optimisation.Accelerate carbon reduction targets.
- Learn more

Quaisr is joining the 2023 Aerospace Xelerated program to unlock value for industrial partners. Read the press release
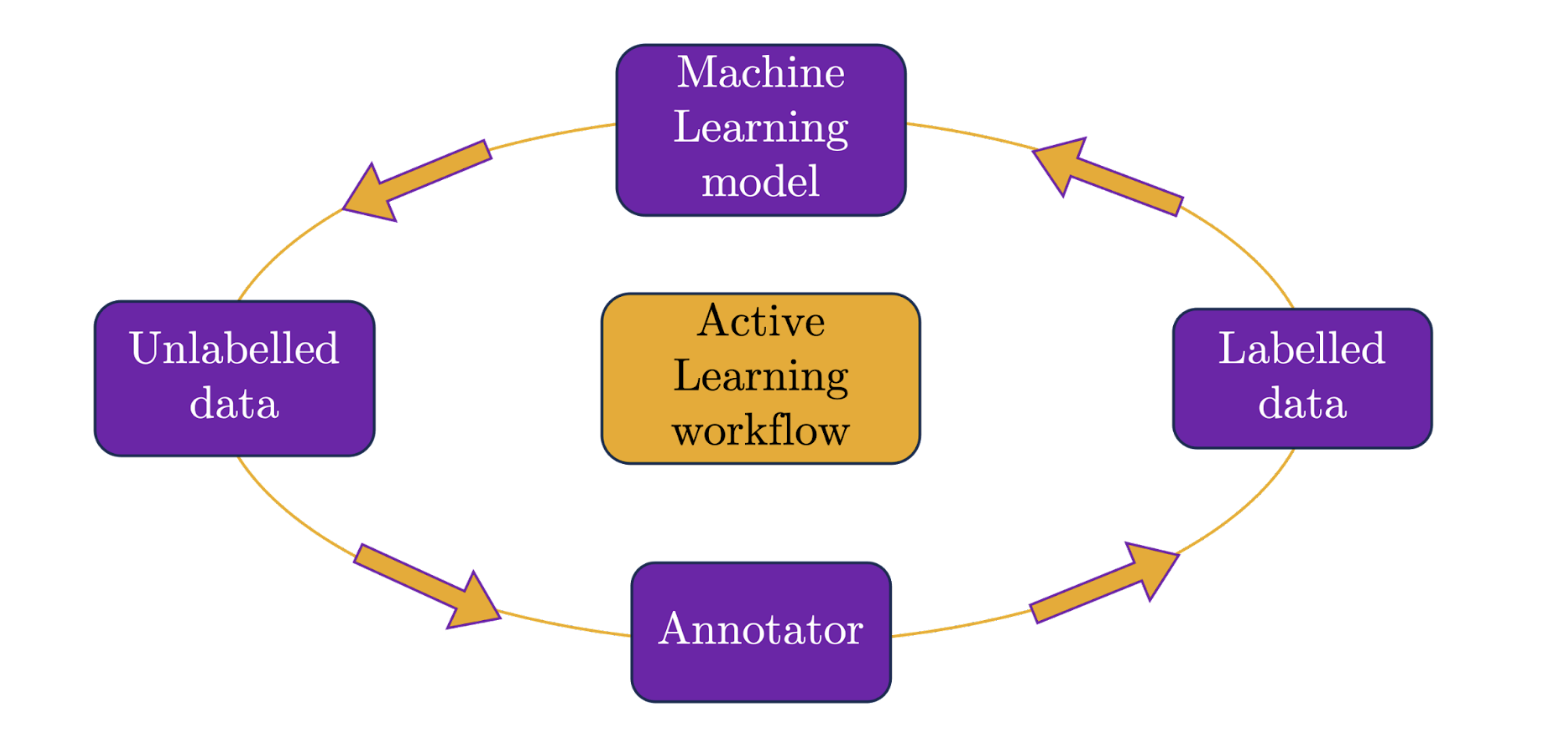
An engineer's guide to Active Learning: Training predictive models efficiently
This blog post sheds light on how active learning can transcend its reputation as a tool exclusive to the realm of cutting-edge data analysis and can become an essential asset in every engineer's toolkit.


Paula Pico
Juan Pablo Valdes
Forging the Future: Insights from the Digital Manufacturing Summit in London
On the bright autumn morning of November 23rd, I had the privilege of attending the Digital Manufacturing Summit in the bustling heart of the City of London.


Assen Batchvarov
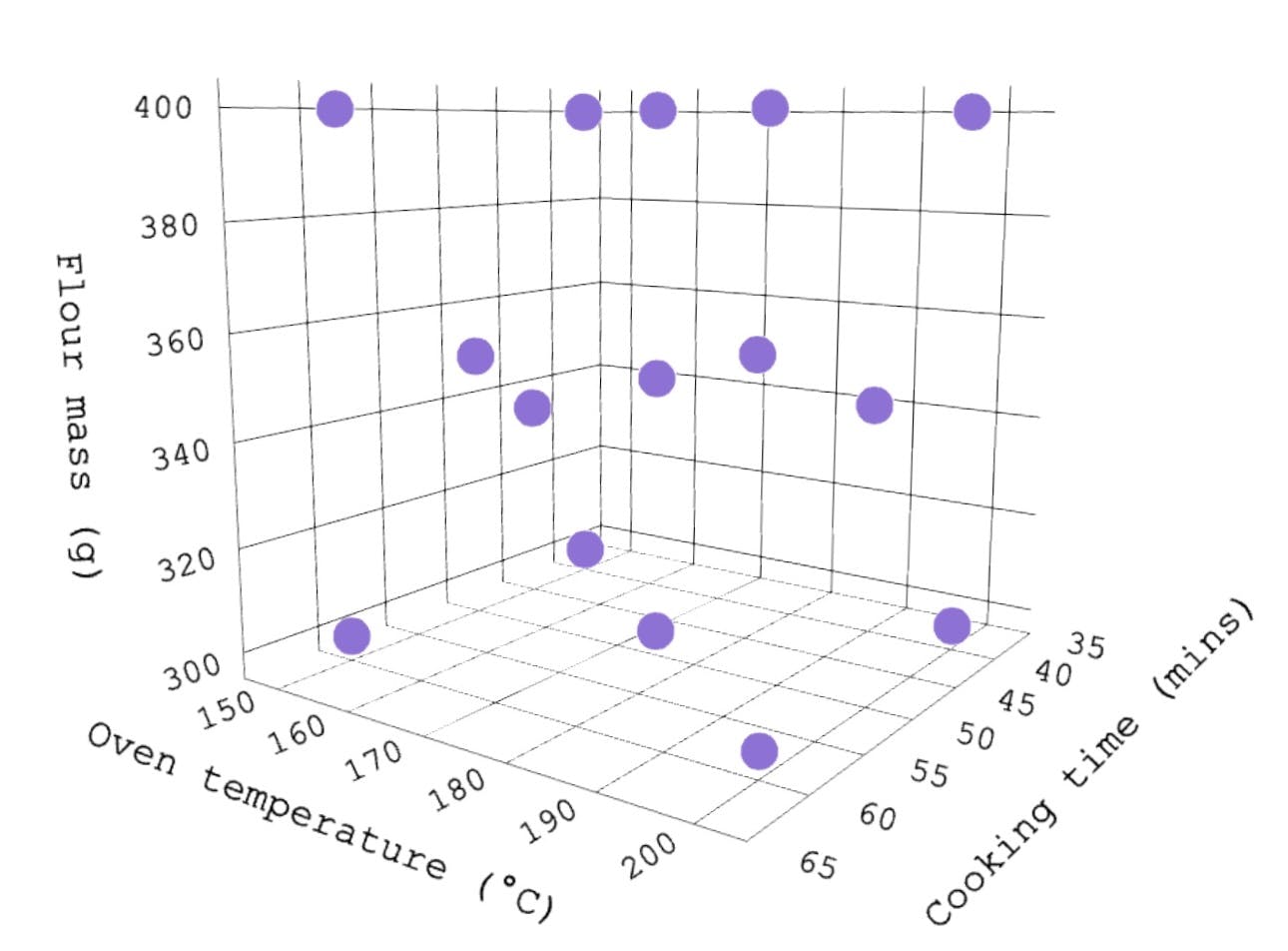
Design of experiments: an introduction
An introduction to Design of Experiments (DoE) with examples. Quaisr is enabling organisations to integrate and adopt DoE techniques at any level.
Paula Pico
Juan Pablo Valdes
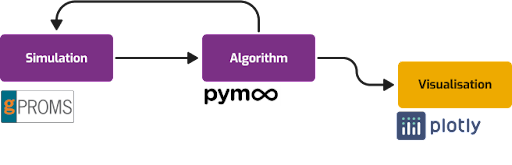
The trade-off: Linking commercial process simulations with AI-based multi-objective optimisation
A story using Quaisr to connect multi-objective optimisation with a styrene production process example in gPROMS
Assen Batchvarov
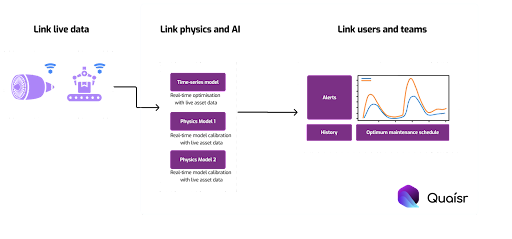
System Identification for Smart Maintenance: A Practical Example
A practical example demonstrating how practitioners can use the Quaisr platform for system identification in the context of anomaly detection.
Paula Pico
Juan Pablo Valdes
The art and science of prevention — Real-time system identification for smart maintenance
Quaisr is enabling business leaders and practitioners to advance predictive maintenance and adopt data streaming within their organisations.

Paula Pico
Juan Pablo Valdes
Black Holes & Simulations
Quaisr is empowering scientists to interpret and understand these gravitational-wave signals.


Madeleine Hall
Faster innovation in the fight against cancer
Quaisr technology is enabling engineers at Multiwave Metacrystal to automate complex physics simulations and integrate them with statistical and machine-learning algorithms.

Assen Batchvarov
Your digital twins must answer three fundamental questions
The use of live data and simulations for the Apollo 13 crew's safe return to Earth is widely recognised as the first real-world use of digital twins.

Assen Batchvarov